


Tabla de Contenidos
En estadística descriptiva existen una serie de medidas que permiten observar distintos aspectos generales de los datos de una población. Algunos se utilizan para medir la tendencia central de los datos, mientras que otros buscan dar una idea de la variabilidad o dispersión de los datos, es decir, de la forma como están distribuidos los datos en torno a dicha tendencia central.
Dos medidas importantes de variabilidad o dispersión son la varianza y la desviación estándar. Estas dos medidas están íntimamente relacionadas una con la otra, sin embargo, existen dos versiones de la varianza y dos correspondientes versiones de la desviación estándar, a saber, la poblacional y la muestral.
Resúmenes estadísticos poblacionales frente a muestrales
Cabe destacar un hecho de gran importancia y es que, en estadística, generalmente existen dos versiones de cada una de las medidas que resumen el comportamiento de una serie de datos y que se utilizan en contextos diferentes.
Para empezar, debemos distinguir entre datos de una población (o datos poblacionales) y datos de un subconjunto de dicha población, a lo que se le denomina muestra. A pesar de que matemáticamente los datos poblacionales y los datos muestrales son indistinguibles, desde el punto de vista conceptual son muy diferentes.
Censos poblacionales
Los datos poblacionales son datos que se obtienen por medio de un censo estadístico, es decir, midiendo o analizando a cada elemento o individuo que conforma a una población (siempre y cuando sea finita, por supuesto). Cuando calculamos medidas de tendencia central o de dispersión para datos poblacionales, obtenemos medidas que resumen el comportamiento general de la población a los que denominamos parámetros poblacionales y los que son valores fijos para una población (es decir, una población solo tiene una media, una moda, una desviación estándar, etc. en un momento determinado). En este caso, estamos haciendo uso de la estadística descriptiva.
Muestreo
Por otro lado, en muchas situaciones diferentes llevamos a cabo un proceso de muestreo para analizar solo algunos elementos de la población, obteniéndose de esta manera datos muestrales. En estos casos, también podemos utilizar las herramientas de la estadística descriptiva para observar el comportamiento general de estos datos, sin embargo, no estamos en realidad haciendo estadística descriptiva sobre la población, solo sobre la muestra.
Los resúmenes numéricos de la muestra no son parámetros, sino que se denominan estadísticas (aunque algunos también los denominan estadísticos). A diferencia de los parámetros, las estadísticas varían de una muestra a otra, así las muestras se obtengan de la misma población. Esto se debe a que, al seleccionar un subconjunto de la población, existen muchas posibles combinaciones de elementos que pueden conformar la muestra. Por esta razón, por lo general, las muestras están conformadas por sujetos, individuos o elementos diferentes, dando lugar a estadísticos diferentes.
El objetivo último de calcular estos estadísticos sobre la muestra, es poder utilizarlos como estimadores de los respectivos parámetros poblacionales. Este proceso de deducir o estimar el comportamiento de los datos poblacionales a partir de los datos muestrales es de lo que se encarga la estadística inferencial. Esto hace que las varianzas y las desviaciones estándar poblacionales y muestrales sean esencialmente diferentes.
Pero, ¿qué son exactamente la varianza y la desviación estándar?
¿Qué es la varianza?
La varianza es una medida de dispersión respecto de la media de un conjunto de datos. Se define como el promedio de las desviaciones cuadradas de todos los datos con respecto a la media. Al ser un promedio de diferencias elevadas al cuadrado, es una cantidad siempre positiva.
¿Qué es la desviación estándar?
Por otro lado, la desviación estándar es simplemente la raíz cuadrada positiva de la varianza. Igualmente mide la dispersión en torno a la media, solo que lo hace en términos de las mismas unidades de los datos y de la media. Esto hace que sea más fácil de entender e interpretar que la varianza.
Como la desviación estándar se calcula como la raíz cuadrada de la varianza, no tiene sentido hablar de desviación estándar poblacional y muestral sin hablar de la varianza poblacional y muestral.
En las siguientes secciones se describirá en detalle las diferencias más importantes entre estas medidas comunes de dispersión en torno a la media.
Diferencia 1: Las desviaciones estándar y varianzas de la población y de la muestra se representan por medio de símbolos diferentes
La primera diferencia que debemos considerar al comparar la varianza poblacional y muestral, y la desviación estándar poblacional y muestral es el símbolo que se utiliza para representarlas. En estadística, los resúmenes numéricos poblacionales o parámetros por lo general se representan utilizando letras griegas, mientras que las versiones muestrales o estadísticos se representan con las letras equivalentes del alfabeto latino.
En este sentido, la varianza y la desviación estándar poblacional se asocian ambas con la letra griega sigma minúscula mientras que las versiones muestrales se representan con la letra s. Es decir, la varianza poblacional es σ2 y la desviación estándar poblacional es σ, mientras que la varianza muestral se representa con s2 y la desviación estándar muestral se representa con s.
Diferencia 2: Se calculan por medio de fórmulas diferentes
Tanto la desviación estándar poblacional como la muestral se calculan como la raíz cuadrada positiva de la respectiva varianza, es decir:
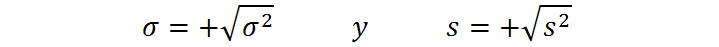
Sin embargo, las varianzas poblacionales y muestrales se calculan por medio de fórmulas ligeramente distintas. En el caso de la varianza poblacional, esta se calcula como la media de las desviaciones cuadradas de cada dato respecto a la media poblacional. Es decir, se calcula mediante una de las siguientes expresiones equivalentes:
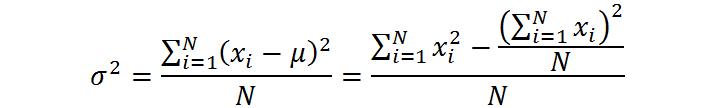
Donde xi representa el valor de cada dato en la población, μ representa la media poblacional y N es el tamaño de la población. Por lo tanto, la desviación estándar poblacional se calcula como:
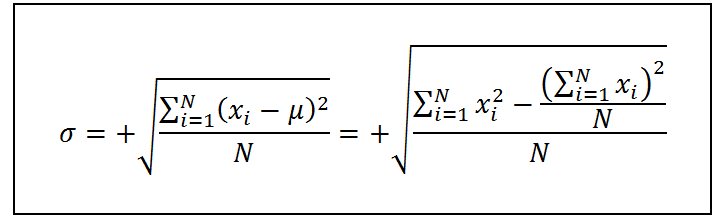
En cambio, en lugar de dividirse entre el número de datos, n, como sería de esperarse, la varianza de la muestra se calcula dividiendo la sumatoria de las desviaciones cuadradas respecto a la media muestral entre n – 1. En otras palabras, la varianza muestral se calcula como:
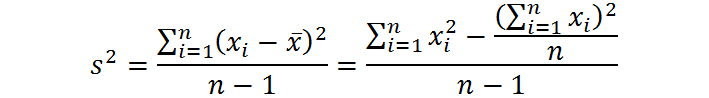
Donde xi representa el valor de cada dato en la muestra, x̄ representa la media muestral y n es el tamaño de la muestra. En vista de lo anterior, la desviación estándar de la muestra se calcula como:
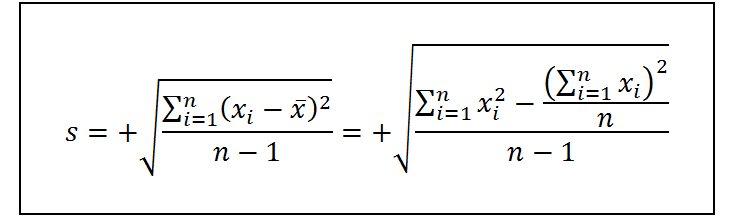
Justificación para dividir entre n – 1 en lugar de n
Una pregunta común que surge al comparar las desviaciones estándar de la población y de la muestra es ¿por qué se divide entre n – 1 y no entre n? La razón es muy sencilla.
Como se mencionó anteriormente, el cálculo de estadísticos como la desviación estándar muestral buscar establecer estimadores que se acerquen lo más posible a los respectivos parámetros poblacionales. Esto quiere decir que, la desviación estándar muestral debería calcularse de manera tal que el resultado sea lo más parecido posible a la desviación estándar poblacional.
Esto sugeriría que deberían calcularse con fórmulas equivalentes, pero esto no siempre es así. El problema es que la desviación estándar muestral mide la dispersión en torno a la media muestral, y no a la media poblacional. A pesar de que la media muestral es un estadístico que se utiliza como estimador de la media poblacional, no es exactamente igual a la misma. Esto hace que los valores individuales de cada muestra estén más cerca de la media muestral (que es, en efecto, la medida de tendencia central de dichos datos) que de la media poblacional. Como consecuencia, una desviación estándar muestral calculara con la misma fórmula que la desviación estándar poblacional (reemplazando la media poblacional por la muestral y el tamaño de la población con el tamaño de la muestra) daría un valor necesariamente menor de lo que sería la desviación respecto a la media poblacional.
Para corregir esta discrepancia, se le resta una unidad al denominador para hacer que la desviación estándar muestral sea mayor, y, por lo tanto, más parecida a la desviación estándar poblacional.
Diferencia 3: Rara vez son iguales
Independientemente de las correcciones que se le pueda hacer a la desviación estándar de la muestra, esta rara vez es igual a la desviación estándar de la población. Esto se debe a que, dentro de una población, los datos pueden variar de manera aleatoria, por lo que distintas muestras darán como resultado distintas desviaciones estándar muestrales. De hecho, existe toda una distribución de posibles valores de las desviaciones estándar muestrales en función del tamaño de la muestra.
Diferencia 4: La desviación estándar de la muestra siempre se puede conocer o determinar, mientras que la desviación estándar poblacional casi nunca se conoce con certeza
Otra diferencia importante entre estas dos medidas de dispersión es que la desviación estándar poblacional (y, de hecho, cualquier parámetro poblacional) rara vez se conoce. Esto se debe, en algunos casos, a limitaciones técnicas o económicas ya que resulta muy costoso y, además, poco probable alcanzar a medir absolutamente todos los datos de una población. En otros casos, determinar los parámetros poblacionales es simplemente imposible, sea porque la población es infinita, o simplemente porque no tenemos acceso a todos los elementos que la conforman.
En otras palabras, casi nunca conocemos todos los N valores de xi de una población, imposibilitando el cálculo de la media, de la varianza y, por extensión, de la desviación estándar de la población. Lo mejor que podemos llegar a conocer es una estimación puntual de un parámetro como la desviación estándar, o un intervalo de valores dentro del cual tenemos cierto nivel de confianza de que se encuentra la desviación estándar u otro parámetrode la población.
En el caso de las muestras, en cambio, sí conocemos todos los datos, por lo que siempre podemos calcular la desviación estándar de cualquier muestra, sea cual sea su tamaño.
Resumen de las diferencias entre las desviaciones estándar de la población y de la muestra
La siguiente tabla resume las diferencias entre la desviación estándar poblacional y la desviación estándar muestral discutidas en las secciones precedentes:
| Característica | Desviación estándar poblacional | Desviación estándar muestral |
| Símbolo | σ | s |
| Se calcula para | Datos poblacionales | Datos muestrales |
| Rama de la estadística en la que se utiliza | Estadística descriptiva | Estadística inferencial |
| Tipo de medida | Parámetro | Estadístico |
| Fórmula | Se divide entre N, el tamaño de la población | Se divide entre n – 1, donde n es el tamaño de la muestra |
| Variabilidad | Es fija para una población determinada en un momento determinado | Varía de una muestra a otra, sin importar que las muestras sean del mismo tamaño y tomadas de la misma población |
| Certeza en su valor | Por lo general es desconocida. Solo se posee una estimación de la misma | Se conoce para cada muestra |
Referencias
Centros comunitarios de aprendizaje. (s. f.). La Desviación Estándar. http://www.cca.org.mx/cca/cursos/estadistica/html/m11/desviacion_estandar.htm
Levy Sarfin, R. (s. f.). Cuál es la diferencia entre la muestra y la desviación estándar de la población. La Voz. https://pyme.lavoztx.com/cul-es-la-diferencia-entre-la-muestra-y-la-desviacin-estndar-de-la-poblacin-5641.html
MateMóvil. (2021, 1 enero). Varianza y desviación estándar, ejemplos y ejercicios. https://matemovil.com/varianza-y-desviacion-estandar-ejemplos-y-ejercicios/
Molina, M. (2016, 27 enero). ¿Por qué sobra uno? Estimando parámetros de la población. AnestesiaR. https://anestesiar.org/2016/por-que-sobra-uno-estimando-parametros-de-la-poblacion/
Serra, B. R. (2020, 26 octubre). Desviación típica o estándar. Universo Formulas. https://www.universoformulas.com/estadistica/descriptiva/desviacion-tipica/
